
We Develop the World’s First End-to-End Speech Foundation Model from Japan
Speech GenAI is still in the pre-GPT3 era. We build Speech Foundation Models that scale massively across tasks, domains, and languages.
Latest News
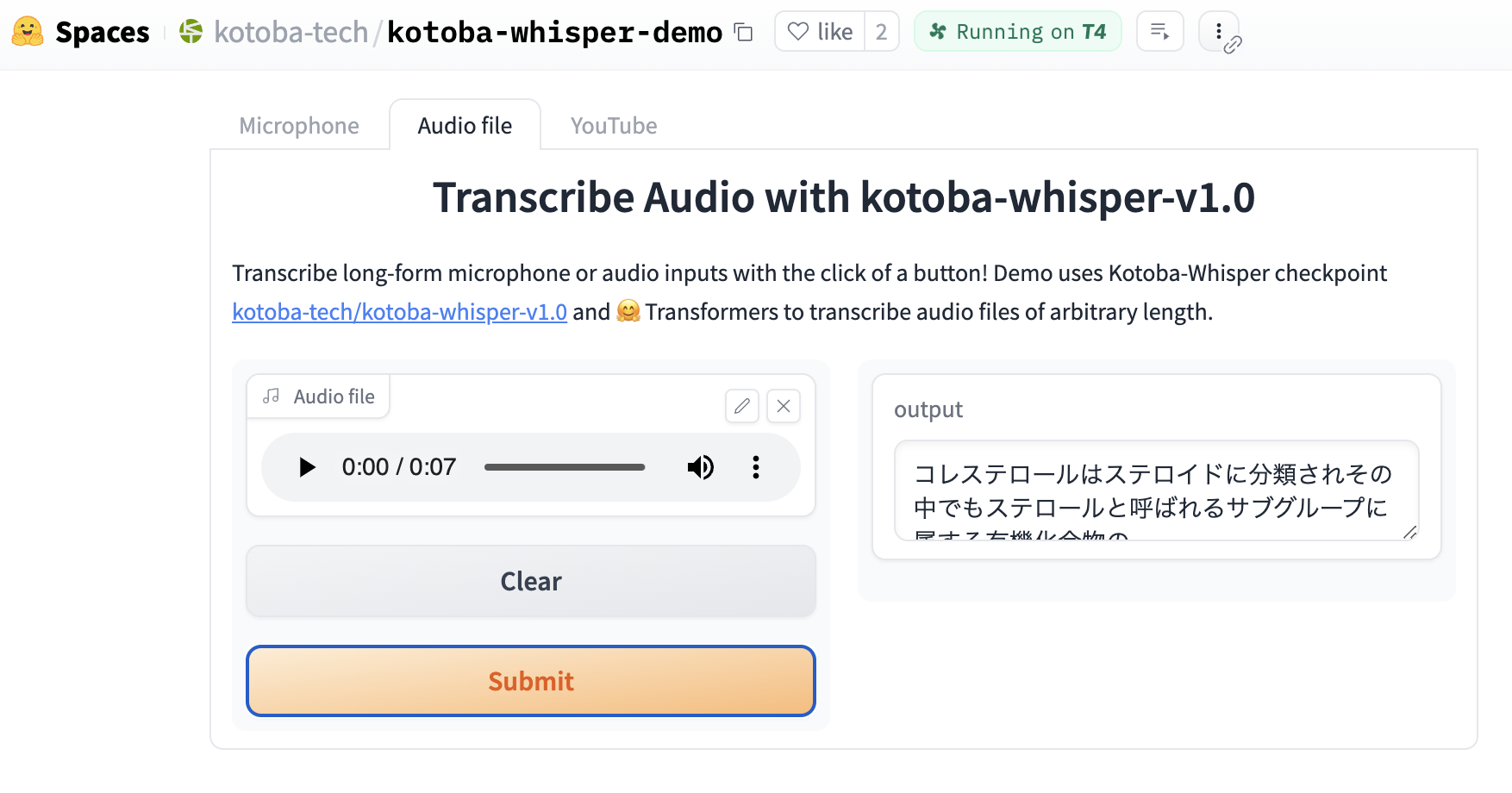
2024/4/16 Kotoba-Whisper 1.0 Release
Kotoba’s fast Japanese ASR (text-to-speech) model. Speeds up Open AI’s best ASR model (Whisper Large) by 6.3x with similar/better performance. Try our demo or open-sourced codebase.

2024/3/22: Kotoba-Speech 0.1 Release
Kotoba’s first end-to-end speech foundation model. Outperforms the speech quality of Amazon, ElevenLabs, Google, and Narakeet. Try our demo or open-sourced codebase.

Kotoba AI Suite
-
The World’s First Speech Foundation Model. Currently supports Japanese speech generation, voice cloning, and customization (e.g., dialects and other languages. Try our demo or open-sourced codebase.
-
Kotoba’s fast Japanese ASR (text-to-speech) model. Speeds up Open AI’s best ASR model (Whisper Large) by 6.3x with similar/better performance. Try our demo or open-sourced codebase.
-
First-ever Japanese/English Mamba, trained on 200B tokens. The performance is competitive to transformers with similar sizes, with a 2x-3x inference speedup. Check our open-soured codebase.
Get in touch.
It all begins with an idea. Maybe you want to launch a business. Maybe you want to turn a hobby into something more. Or maybe you have a creative project to share with the world. Whatever it is, the way you tell your story online can make all the difference.
Want to contribute? Join our developer community.
Join our Discord community and suggest improvements or new features.